Bereits letzte Woche über haben wir uns eine neue Lektüre vorgenommen. Wir genießen die Morgen bei Sonnenschein mit einem Kapitel aus dem pragmatischen Programmierer.
Für unsere DataModelEngine haben wir einen GenericRowMapper implementiert. Bisher haben die RowMapper aus JDBI gute Arbeit geleistet. Nun haben wir neue Anforderungen, die scheinbar nicht mehr erfüllt werden können. Wir benötigen nun die Möglichkeit komplexere Joins abzusetzen und dabei unter anderem eine Tabelle mehrfach zu joinen, da es sich je nach Fall um eine andere Relation handeln kann.
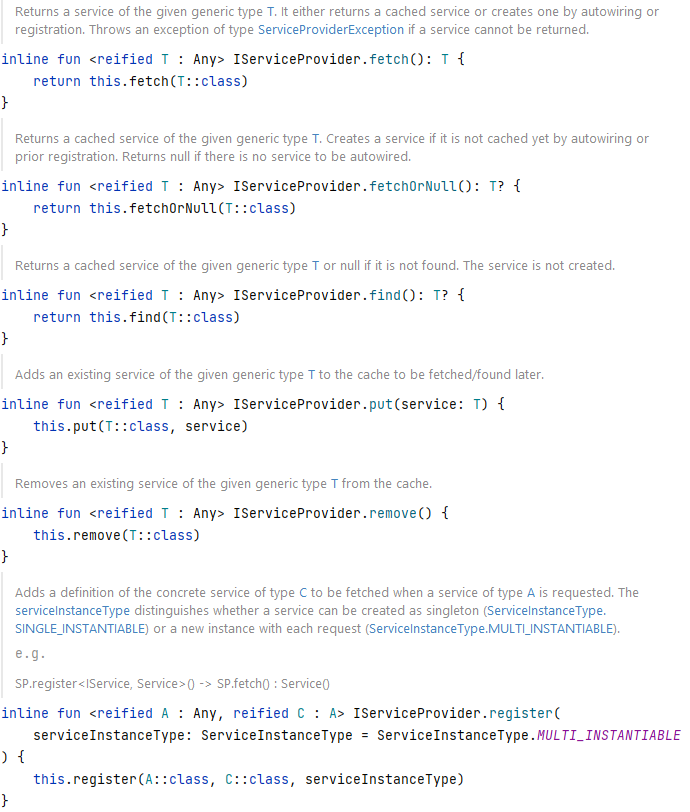
Im Kern nutzt unser RowMapper die Funktionen aus JDBI. Beispielsweise kann auf das Ergebnis eines Selects typesafe zugegriffen werden. Ein Int-Wert ist ein Int-Wert und kein Wert vom Typ String. Allerdings muss der Aufrufer der JDBI-Funktionen (also unser RowMapper) wissen, ob er GetString(ColumnId) oder GetTimestamp(ColumnId) aufrufen muss. Das Mappen von Rows unterteilt sich in zwei Phasen. Es gibt eine Analyse- und eine Mapping-Phase.
Die Analyse-Phase besteht aus drei Schritten:
- EntityCache initialisieren
Da im Falle von Joins mehrere Spalten zu einer Entität gehören können, bestimmen wir für jede Spalte einen Entity Cache. Für jede Spalte, die sich auf die selbe Entität bezieht, verwenden wir den selben Cache. Beim ersten Zugriff auf den Cache wird eine Instanz der Entität erzeugt.
Der Zugriff auf diesen Cache passiert mittels ColumnId (1,2,3,4, etc.).
- ColumnValueMapper initialisieren
Für jede Spalte wird ein ValueMapper instanziiert. Diesem wird eine Funktion zugewiesen, die bei Ausführung bspw. JDBIs resultSet.GetInt() oder resultSet.GetString() aufruft. Außerdem kennt der ValueMapper die Spalte, für die er zuständig ist. D.h. in der Mapping-Phase werden die einzelnen Mapper aufgerufen, die Zeilendaten werden übergeben und der Mapper kann zielsicher auf der jeweiligen Spalte seine ihm übergebene Funktion zum Mappen anwenden. Wodurch die Ausführung sehr performant ist.
Auch dieser Zugriff auf diesen Cache erfolgt mittels ColumnId (1,2,3,4, etc.). - KMutableProperty bestimmen
Als letztes benötigen wir die Properties, da die PropertySetter aufgerufen werden müssen, um einen Property Wert zu setzen. Auch diese cachen wir für einen schnellen Zugriff.
Am Ende sieht die Initialisierung wie folgt aus:
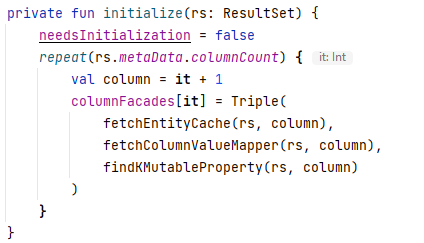
Am Ende mussten wir unseren EntityCache, ColumnValueMapper und KMutableProperty nur noch mit den gelesen Daten füttern. Auf der erzeugten Entität, für das jeweilige Attribut, wird der gemappte Wert gesetzt und wir hatten unser gewünschtes Ergebnis.
Interessant ist die Vorgehensweise für uns, da wir das Cachen von Funktionen für einen späteren und performanten Aufruf so noch nicht verwendet haben.